前端笔记(合集)
什么是ES6?ES6和JS有什么区别?#
ES6是一个标准,全名是ECMAScript6.0,而JavaScript是ES6的一个实现。
什么是CommonJS和NodeJS?为什么会有它们?#
commonjs是一种规范,nodejs是这种规范的实现。 JavaScript的标准定义API是为了用于构建基于浏览器的应用程序,但是没有一个用于更广泛的应用程序的标准库。最初的JavaScript只能用来给浏览器使用。 而CommonJS API定义了很多普通应用程序使用的API,从而填补了这个空白。它的究极目标是提供一个类似Python、Ruby和Java的标准库。这样开发者就可以使用CommonJs API来编写程序,然后这些应用可以运行在不同的JavaScript解释器和不同的主机环境中。
JavaScript和NodeJs的区别是什么?#
JavaScript:
- ECMAScript(语言基础,如语法、数据类型结构、以及一些内置对象)
- DOM(一些操作页面元素的方法)
- BOM(一些操作浏览器的方法)
NodeJS:
- ECMAScript(语言基础,如语法、数据类型结构、以及一些内置对象)
- os(操作系统)
- file(文件系统)
- net(网络系统)
- database(数据库)
总结:前端和后端js的共同点就是,他们的语言基础都是ECMAScript,只是他们扩展的东西不同,前端需要操作页面元素,于是扩展了DOM,也需要操作浏览器,于是扩展了BOM。而服务端的js则也是基于ECMAScript扩展出了服务端所需要的一些API。常见的后台语言需要有操作系统的能力,于是扩展了os,需要有操作文件的能力,于是扩展了file文件系统,需要操作网络,于是扩展出了net网络系统,需要操作数据,于是扩展出了database能力。
函数执行中的理解#
- 进入执行上下文,激活变量对象VO,变为活动对象AO(Activation object)
- AO对象默认初始化arguments对象,存有函数形参。
- 进入执行上下文后,将函数内的变量、函数解析到AO中,函数中的形参在AO中存值,函数内的实参在AO中是undefined,然后顺序执行代码,一步一步给AO中的参数赋值。
JS中堆与栈的使用#
JS中基本类型保存在栈内存中,因为这些类型再内存中分别占有固定大小的空间,通过按值访问。引用类型保存在堆内存中,因为这种值的大小不固定,因此不能保存在栈内存中,但是内存地址大小是固定的,可以将地址放在栈中。 查找引用类型的值时,先去栈中查找,读取内存地址,再通过地址找到堆内存中的值。
小青离京,好好学习~
由一个小问题分析JS的赋值问题#
问题
var a = {n: 1};var b = a;a.x = a = {n:2}; console.log(a.x); //输出是undefinedconsole.log(b.x); //输出是{n: 2}
重点
- JS引擎对赋值表达式的处理过程
- 赋值运算的右结合性
JS引擎怎么计算赋值表达式呢 比如A = B
- 计算表达式A,得到一个引用refA
- 计算表达式B,得到一个值valueB
- 将valueB赋给refA指向的名称绑定
- 返回valueB
右结合性 所谓结合性,是指表达式中同一个运算符出现多次时,是左边的优先计算还是右边的 赋值表达式是右结合的,也就是说: A1 = A2 = A3 = A4 等价于 A1 = (A2 = (A3 = A4))
所以,表达式是从左往右找到引用,从右往左进行赋值 当JS引擎运行到a.x = a = {n:2};时,从左往右求引用,a.x的引用是在{n:1,x:undefined}的x,a的引用是对象{n:1}。从右往左求值,a指向{n:2},b.x指向{n:2},b的地址还是原先a对象处的地址
闭包的变量并不是保存在栈内存中,而是保存在堆内存中#
闭包的简单定义:函数A返回了一个函数B,并且函数B中引用了函数A的变量。函数B就称为闭包。
typeof(null)是object,可以将引用变量赋值为null。typeof(undefined)为undefined。
垃圾回收算法#
- 引用计数法:看一个对象是否有指向它的引用。 弊端:循环引用导致内存泄露。
- 标记清除法:从根部(JS中为全局对象)出发,定时扫描内存中的对象,能从根部到达的对象,都是还需要使用的。无法从根部到达的对象,标记为不再使用,稍后进行回收。
- 经验法则:连续五次垃圾回收之后,内存占用一次比一次大,就存在内存泄露。
初始定义的模块#
在NodeJs中,编写稍大一点的程序时一般会将代码模块化,将代码合理拆分到不同的JS文件中,每一个文件都是一个模块,文件路径就是模块名。 编写每个模块时,都有require、exports、module三个预定义好的变量可以使用。
require模块#
require函数用于在当前模块中加载和使用别的模块,传入一个模块名,返回一个模块导出对象。模块名可以用相对路径,或者绝对路径,模块名中的.js后缀也可以省略。
var foo1 = require('./foo');var foo2 = require('./foo.js');var foo3 = require('/home/usr/foo');var foo4 = require('/home/usr/foo.js');以上四个变量都是同一个模块的导出对象exports模块#
exports对象使当前模块的导出对象,用于导出模块共有方法和属性。别的模块通过require函数使用当前模块时,就是当前模块的exports对象。如:
exports.hello = function(){ console.log('Hi~');}module模块#
通过module对象可以访问到当前模块的一些相关信息,但最多的用途是替换当前模块的导出对象。
主模块#
通过命令行参数传递给NodeJs启动的模块被称为主模块。主模块负责调度组成整个程序的其他模块完成工作。 当主模块中使用require函数之后,导入该模块。在内存空间中生成该引入模块的对象,就算在主模块中使用不同的变量反复导入统一模块,此模块也只初始化一次。只不过新声明的变量也指向第一次生成的对象。
代码的组织和部署#
JS模块的基本单位是单个JS文件,但复杂些的模块往往是由多个子模块组成。为了便于管理和使用,可以把由多个子模块组成的大模块称作包,并把所有子模块放在同一个目录中。
index.js#
当模块的文件名是index.js时,加载模块时可以使用模块所在目录的路径代替模块文件路径。以下两条语句等价。
var cat = require('/home/usr/lib/cat');var cat = require('/home/usr/lib/cat/index');这样处理之后,只需要把包目录路径传递给require函数,感觉上整个目录被当做单个模块使用,更有整体感。
package.json#
使用package.json文件,就可以自定义入口模块的文件名和存放位置,并在其中指定入口模块的路径。
{ "name":"cat", "main":"./lib/main.js"}定义好package.js文件之后,就可以使用require('home/user/lib/cat')的方式加载模块(这次入口文件不是index.js,也是直接引用的包目录的路径),NodeJs会根据包目录下的package.json找到入口模块所在位置。
命令行程序#
使用NodeJs编写的东西,要么是一个包,要么是一个命令行程序,而前者最终也会用于开发后者。如果在部署代码的时候用一些技巧,就可以让用户觉得自己是在使用一个命令行程序。 Linux下
- 可以把JS文件当做shell脚本来运行,在编写完成的js程序第一行加上
#!/usr/bin/env node- 然后赋予该js文件可执行的权限(node-echo.js是文件名,该文件的路径时/home/user/bin)
chmod +x /home/user/bin/node-echo.js- 在PATH环境变量中指定的某个目录下,例如在/usr/local/bin中创建一个软链文件,文件名与我们希望使用的终端命令同名
sudo ln -s /home/user/bin/node-echo.js /usr/local/bin/node-echo这样处理以后,我们就可以在任何目录下使用node-echo命令了
工程目录#
一个完整的工程目录,应该提供命令行模式和API模式两种使用方式,并且我们会借助第三方包来编写代码。除了代码以外,一个完整的程序还应该有自己的文档和测试用例。如下:
-/home/usr/workspace/node-echo/ #工程目录 -bin/ #存放命令行相关代码 node-echo +doc/ #存放文档 -lib/ #存放API相关代码 echo.js -node_modules/ #存放三方包 + argv/ +tests/ #存放测试用例 package.json #元数据文件 README.md #说明文件不同的文件夹存放了不同类型的文件,并通过node_modules目录直接使用三方包名加载模块。此外,定义了package.json之后,node-echo目录也可以被当做一个包来使用。
使用npm的一些东西#
- 可以上npmjs.org来搜索自己想要的包
- npm install是下载最新版本的包,如果想下载指定版本的话,可以加@符号,比如 npm install vue@0.0.1
- 当引入的三方包比较多时,可以在package.json中添加依赖项,然后在工程目录中使用npm install,会自动安装所依赖的包。
- npm install node-echo -g,为例,-g表示全局安装,安装之后NPM会自动创建好Linux系统需要的软链文件或Windows系统下的.cmd文件。 在linux系统下,会安装到/usr/local/lib/node_modules/这里,并且在/usr/local/bin/这里创建软链。
语义版本号#
npm使用语义版本号来管理代码,语义版本号分为X.Y.Z三位,分别代表主版本号,次版本号和补丁版本号。当代码变更时,版本号按以下原则进行更新。
- 如果只是修复了bug,需要更新Z位
- 如果是新增了功能,但是向下兼容,需要更新Y位
- 如果有大变动,向下不兼容,需要更新X位
今天看了promise,一直在说promise是js的实现异步操作的解决方案。中间说了很多事件循环机制,就查了查。看到一篇博客,写的不错,很便于理解。
消息队列#
- 有些文章把消息队列称为任务队列,或者叫事件队列,总之是和异步任务相关的队列
- 可以确定的是,它是队列这种先入先出的数据结构,和排队是类似的,哪个异步操作完成的早,就排在前面。不论异步操作何时开始执行,只要异步操作执行完成,就可以到消息队列中排队
- 这样,主线程在空闲的时候,就可以从消息队列中获取消息并执行 *消息队列中放的消息具体是什么东西?消息的具体结构当然跟具体的实现有关。但是为了简单起见,可以认为:消息就是注册异步任务时添加的回调函数。
事件循环#
下面来详细介绍事件循环。下图中,主线程运行的时候,产生堆和栈,栈中的代码调用各种外部API,异步操作执行完成后,就在消息队列中排队。只要栈中的代码执行完毕,主线程就会去读取消息队列,依次执行那些异步任务所对应的回调函数
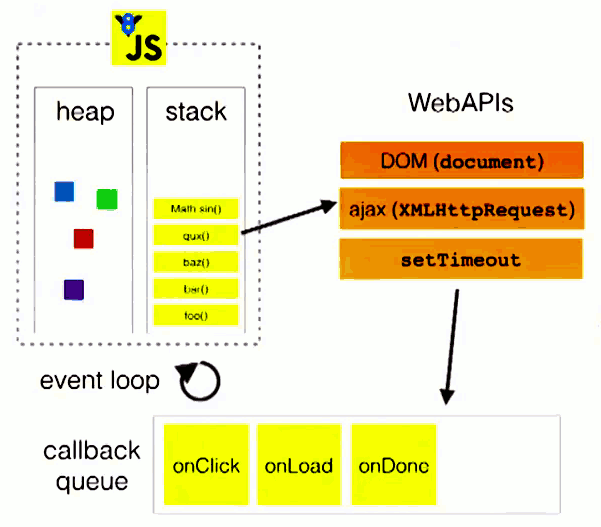
详细步骤如下:
- 所有同步任务都在主线程上执行,形成一个执行栈
- 主线程之外,还存在一个"消息队列"。只要异步操作执行完成,就到消息队列中排队
- 一旦执行栈中的所有同步任务执行完毕,系统就会按次序读取消息队列中的异步任务,于是被读取的异步任务结束等待状态,进入执行栈,开始执行
- 主线程不断重复上面的第三步
循环#
从代码执行顺序的角度来看,程序最开始是按代码顺序执行代码的,遇到同步任务,立刻执行;遇到异步任务,则只是调用异步函数发起异步请求。此时,异步任务开始执行异步操作,执行完成后到消息队列中排队。程序按照代码顺序执行完毕后,查询消息队列中是否有等待的消息。如果有,则按照次序从消息队列中把消息放到执行栈中执行。执行完毕后,再从消息队列中获取消息,再执行,不断重复。
由于主线程不断的重复获得消息、执行消息、再取消息、再执行。所以,这种机制被称为事件循环
事件#
为什么叫事件循环?而不叫任务循环或消息循环。究其原因是消息队列中的每条消息实际上都对应着一个事件
DOM操作对应的是DOM事件,资源加载操作对应的是加载事件,而定时器操作可以看做对应一个“时间到了”的事件
背景#
昨天在写代码的时候用到了v-model,出现了一点问题。我在vue的data中定义了一个空的对象obj: {},在某个ajax操作中会对这个对象进行操作,赋予很多属性,比如说 obj.name = 'lrq'。在html中我将这个属性绑定在一个input输入框中<input v-model="obj,name">,但是没有达到想要的效果,前端页面既没有显示数据,console打印出来的数据也是空。解决方案:在定义obj对象的时候要直接加上这个属性,就可以监听到变化了。 obj: {name: ''}.借着这个机会深入了解一下vue的双向绑定。
什么是双向绑定?#
v-model实现的功能就是双向绑定,前端页面的dom元素和js中的数据进行绑定。当前端元素,比如说是一个input输入框,内容发生改变后,相应的js中与之相关的数据也会发生改变。同理,当js中处理一些业务逻辑后,对数据进行了修改,前端页面中的input输入框的内容也会发生变化。这就是双向绑定。
双向绑定是怎么实现的?#
- dom元素内容发生变化,会触发相应的事件。比如说input元素的
onchange、oninput事件,可以在事件中进行js中数据的同步修改。 - 而js中的数据修改之后,怎么反映到dom元素中呢?这里用到了数据劫持。非常细节的底层现在我也还不是很懂,但大概的流程基本知道了。首先在初始化数据的时候要使用Object.defineProperty()方法重写数据的set和get方法,在实际的使用中,给数据赋值实际上就是调用了set方法,这样就可以在set方法中进行一些操作,比如说把set后的value直接写到前端的页面中,进而达到js中数据改变关联到前端页面同步改变的效果。
v-model的语法糖#
v-model相当于是一个语法糖,比如以下代码
<input type="text" v-model="suger">
<input type="text" v-bind:value="suger" v-on:input="$event.target.value">这两段代码产生的效果是一样的,这就是语法糖的意思。
需要进一步了解的东西#
看了很多博客,说是在数据劫持中使用了发布者订阅者模式,具体的看了一些还是不太清晰,日后再好好看一下,再回来补充。